December 17th, 2024 • Comments Off on Power efficiency: throttling for Sustainability
The rise of AI applications has brought us soaring power demands and strains on the environment. Google reported a 13% emission increase thanks to AI, their footprint is huge, some power grids are struggling, new data centers are about to use enormous amounts of energy, and the reporting of all this isn’t great either sometimes (btw try a traditional search before using a chat bot if you care about the environment).
So the challenge is: how can we make AI, and HPC/HTC applications more energy-efficient without sacrificing too much performance?
The good news is, that AI, HPC, and HTC workloads are very flexible – they can e.g. be shifted in time and space to align with the availability of e.g. green energy. HPC systems, using job schedulers like Grid Engine, LSF, and SLURM can be used for this. But what if we could add another dimension to this energy-saving toolkit? Enter CPU and GPU throttling.
Throttling CPU and GPU frequencies to lower power draw levels is not a new idea. Research from Microsoft and others has shown that modest performance reductions can result in substantial energy savings. The underlying principle is dynamic voltage and frequency scaling (DVFS). To illustrate this point, let’s consider a specific example: here I’m running a Phi 3.5 LLM on an Arc GPU for inference. Performance is measured through the token creation time and we’ll observe the P-99 of the same. Just a small adjustment in performance can lead to significant power savings. For instance: by adjusting the GPU frequency, while only sacrificing a 10% in performance, we can observed up to 30% power savings.
 (Click to enlarge)
(Click to enlarge)Btw, as we’re testing an AI workload, the performance for this example depends heavily on memory bandwidth. With lower GPU frequency, memory bandwidth usage is lower. Again showing that frequency scaling is an effective way to control memory bandwidth. This explains low P99 compute latency that improves over time as frequency is increazed. The application was in general bottle necked. From around 1500MHz onward, memory bandwidth stabilizes, and performance gets more consistent.
 (Click to enlarge)
(Click to enlarge)While the results shown here use a low-range GPU, the principles hold true for larger systems. For example, a server with 8 GPUs, each with a TDP of ~1000W, could save hundreds of watts per server. Imagine the compounded impact across racks of servers in a data center. By incorporating techniques like throttling, we can make meaningful strides toward reducing the carbon footprint of AI.
Leveraging the flexibility of workloads—such as the AI examples shown here—can greatly improve system effectiveness: run faster when green energy is available and slower when sustainability goals take priority. Together, these strategies pave the way for a more sustainable compute continuum.
Categories: Personal • Tags: Artificial Intelligence, Cloud, data center, Edge, system effectiveness, system performance • Permalink for this article
December 12th, 2022 • Comments Off on Intent Driven Orchestration
So let’s start with a bolt statement: the introduction of Microservices/functions and Serverless deployment styles for cloud-native applications has triggered a need to shift the orchestration paradigms towards an intent-driven model.
So what are intents – and what does intent-driven mean? Imagine a restaurant and you order a medium rare steak – the “medium rare” part is the intent declaration. But if we contrast this concept to how orchestration stacks work today – you’d walk into the restaurant, walk straight into the kitchen and you’d say “put the burner on 80% and use that spatula” etc. Essentially declaratively asking for certain amounts of resources/certain way of setup. And obviously, there are a couple of issues with that – you do not necessarily know all the details of the burner. Should it have been set to 80% or 75% maybe? Should it have been 1 core, 500Mb or RAM, sth else? Abstractions and Serverless, anyone?
So why not let app/service owners define what they care about – the objectives of their app/service? For example, “I want P99 latency to be less than 20ms”. That is the “medium rare” intent declaration for an app/service. That is what we’ve been working on here at Intel – and now we’ve released our Intent-Driven Orchestration Planner (Github) for Kubernetes.
Btw.: I shamelessly stole the restaurant metaphor from Kelsey Hightower – for example, check out this podcast. On the P-numbers – again sth that other people have been writing about as well, see Tim Bray‘s blog post on Serverless (part of a Series).
Based on the intents defined by the service owner we want the orchestration stack to handle the rest – just like a good chef. We can do this through scheduling (where/when to place) and planning (how/what to do), to figure out how to set up the stack to make sure the objectives (SLOs) are met.
So why though a planner? The planning component brings sth to the table that the scheduler cannot. It continuously tries to match desired and current objectives of all the workloads. It does this based on data coming from the observability/monitoring stack and tries to reason to enable efficient management. In doing so it can trade-off between various motivations for the stakeholders at play and even take proactive actions if needed – the possibilities for a planner are huge. In the end, the planner can e.g. modify POD specs so the scheduler can make more informed decisions.
Here is an example of that an intent declaration for out Intent Driven Orchestration Planner can look like – essentially requesting that P99 latency should be below 20ms for a target Kubernetes Deployment:
apiVersion: "ido.intel.com/v1alpha1"
kind: Intent
metadata:
name: my-function-intent
spec:
targetRef:
kind: "Deployment"
name: "default/function-deployment"
objectives:
- name: my-function-p99compliance
value: 20
measuredBy: default/p99latency
Again the usage of planners is not revolutionary per se, NASA has even flown them to space – and could demonstrate some nice self-healing capabilities – on e.g. Deep Space 1. And just as Deep Space 1 was a tech demonstrator, maybe a quick note: this is all early days for intent-driven orchestration, but we would be very interested in learning what you think…
So ultimately, by better understanding the intents of the apps/services instead of just their desired declarative state, orchestrators – thanks to an intent-driven model – can make decisions that will lead to efficiency gains for service and resource owners.
Categories: Personal • Tags: Cloud, Edge, Intent-Driven Orchestration, Orchestration, Planning • Permalink for this article
May 14th, 2021 • Comments Off on Write your functions in Rust – with Azure & Rocket
Rust is certainly one of the hot programming languages right now. Besides the cool feature set the language offers, companies – like Microsoft, Intel, Google, AWS, Facebook, etc. – embrace it: krustlet, rust-vmm, firecracker, etc. are all written in Rust. Then there is the newly formed Rust foundation and even in a recent survey by Stack Overflow it comes in on top. So why not programming your functions in Rust as well?
Most Cloud providers offer ways to write your function in Rust: AWS has a Rust based runtime for Lambda – using custom AWS Lambda runtimes, Azure offers it through what they call Azure Functions custom handlers. Both are reasonably similar in usage – as basically all you need to do is create an executable that is triggered by the frameworks when an Event arrives. Btw if you want to run it your function on-premises try the Rust template for OpenFaaS. We’ll look into how to integrate with Azure in the following sections.
Similarly to what is described in the Quickstart – it all starts with creating a new package using cargo:
$ cargo new rusty_function
Within the newly created package we need to edit the dependencies. As the function handler will be called through HTTP, a web framework is needed: rocket is one of the major web frameworks in the Rust ecosystem. Secondly serde can be used to serialize and deserialize data. The dependencies section of the Cargo.toml file will hence look something like this:
[dependencies]
rocket = "^0.4.7"
rocket_contrib = "^0.4.7"
serde = "1.0"
serde_derive = "1.0"
serde_json = "1.0"
Writing the actual logic of the function is pretty straight forward – in main() start a web server that listens to a specific port – as provided by an environment variable:
fn main() {
let port_key = "FUNCTIONS_CUSTOMHANDLER_PORT";
let port: u16 = match env::var(port_key) {
Ok(val) => val.parse().expect("Whoops - not a int..."),
Err(_) => 8080,
};
let config = config::Config::build(config::Environment::Staging)
.address("127.0.0.1")
.port(port)
.finalize()
.unwrap();
rocket::custom(config)
.mount("/", routes![index, hello])
.launch();
}
Notice that two routes are setup in the second to last line of code. The one listening to HTTP GET calls to the main index page, and the actual function that implements our handler. The function for handling the request to the “main page” is not strictly necessary – I did notice however, that the Azure functions framework does make a single HTTP GET call on “/” when the functions starts. Implementing the index function is straight forward hence:
#[get("/")]
fn index() -> &'static str {
""
}
Before implementing the logic of the function itself, note that Azure expected the inputs and outputs to be formatted in a certain way – more details can be found here. Let’s focus on the output of the function and make sure it returns a JSON struct similar to this:
{
"returnvalue": {
"msg": "hello world"
},
"outputs": {
"res": "ok"
}
}
Not all of this will actually be returned to the function caller, but some of it is used by the Azure Functions framework itself – like outputs can contain entries you want to put in a Azure Queue storage, and logs (not shown in the example above) can be used to capture logging information. The actual ReturnValue is later on mapped to a response that is send to the function caller – more on that later.
We’ll use a set of structs to defined the JSON – and use the serde crate to enable serialization:
#[derive(Serialize)]
struct Response {
msg: String,
}
#[derive(Serialize)]
struct OutputBody {
res: String,
}
#[derive(Serialize)]
struct ResponseMessage {
returnvalue: Response,
outputs: OutputBody,
}
Obviously to be more conform with naming conventions in Rust – returnvalue should be called return_value, but Azure is looking for a CamelCase formatted ReturnValue – but luckily allows lower case naming too.
Implementing the actual function is straight forward now – notice the declaration of the /RustFunction route – that is later configured (becoming the name of the function), so the Azure Functions framework knows where to look for the function – more on that in the next steps.
#[post("/RustFunction")]
fn hello() -> json::Json<ResponseMessage> {
json::Json(ResponseMessage {
returnvalue: Response{msg: "hello world!".to_string()},
outputs: OutputBody{res: "ok".to_string()}
})
}
Make sure you use the nightly toolchain (it’s a rocket requirement atm) using the command rustup override set nightly. Also let’s make sure we get a static linked binary using MUSL by defining the following in the file .cargo/config:
[target.x86_64-unknown-linux-musl]
linker = "rust-lld"
The code will compile now using: cargo build –release –target=x86_64-unknown-linux-musl, and we can run it standalone and even trigger the function if we want to. With a simple curl request the function can be tested locally. For the build command above to work you might need add the musl target to your system using rustup target add x86_64-unknown-linux-musl.
$ curl -X POST localhost:8080/RustFunction
{"returnvalue":{"msg":"hello world"},"outputs":{"res":"ok"}}
Integration with Azure Functions
So far everything has been pretty much generic, to make this function run on Azure some integration steps are required. The files required to do this can be created using the Azure Function Core Tools or probably with some help of your IDE. The command func new can be used to create the right templates. Make sure to configure it using the Custom Handler and HTTP Trigger – name the function e.g. RustyFunction matching the route defined earlier.
In the file host.json we now configure the field defaultExecutablePath to match our binary name – in our case rusty_function. The file RustyFunction/function.json should contain the following:
{
"bindings": [
{
"authLevel": "anonymous",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
Notice that within this configuration file we can define the HTTP verbs and also define how Azure Functions should handle the return values – note the $return that basically tells the framework to return whatever is set for the field ReturnValue (see JSON structure earlier) to the caller.
At this point in time, the function can be published to Azure or run locally using func start. Noticed that when calling the function through he framework we just get the “hello world” message back when testing it with curl:
$ curl -X POST http://localhost:7071/api/RustFunction -d ""
{"msg": "hello world"}
Performance
Finally let’s look at the performance of the function when being deployed on Azure. Therefore let’s compare a function written in Python and one written in Rust, both performing the same task: calculating the area of a circle given a radius.
This is not a totally fair comparison – as we are comparing apples to oranges a bit: the programming languages and their stacks are different, their deployment style differs (custom Linux based runtime vs optimized Python runtime). Also note we are only looking at HTTP triggers (coming with an overhead of serialization and deserialization, running a web framework etc.) – none of the other goodies that are available – and obviously hitting a function with a workload generator to look at performance goes a bit against the purpose of function: the frequency of invocation is really “high” and for this kind of call frequency a micro service style deployment might have been way better. Also some aspects of what influences latencies etc. are not in our control – the internet connection, the framework itself, etc.. Anyhow some numbers are better then no numbers.
Both functions have been deployed in Azure West Europe region – the following plot shows the latency percentiles for the function calls. And no surprise, Rust does well (but do notice the tail latency – that could really hurt overall performance – especially if you have multiple of these functions in your environment):
 (Click to enlarge)
(Click to enlarge)Another benefit of writing our function in Rust – the binary is tiny; Just about 5.6M in this case – so you can very easily package it up in a tiny container and run that in Azure, or OpenFaaS or … . Now it would be great to be able us other event triggers and concepts like function orchestration provided by e.g. Durable Functions as well in future.
Categories: Personal • Tags: Cloud, FaaS, Rust, Serverless • Permalink for this article
July 25th, 2016 • Comments Off on Insight driven resource management & scheduling
Future data center resource and workload managers – and their [distributed]schedulers – will require a new key integrate capability: analytics. Reason for this is the the pure scale and the complexity of the disaggregation of resources and workloads which requires getting deeper insights to make better actuation decisions.
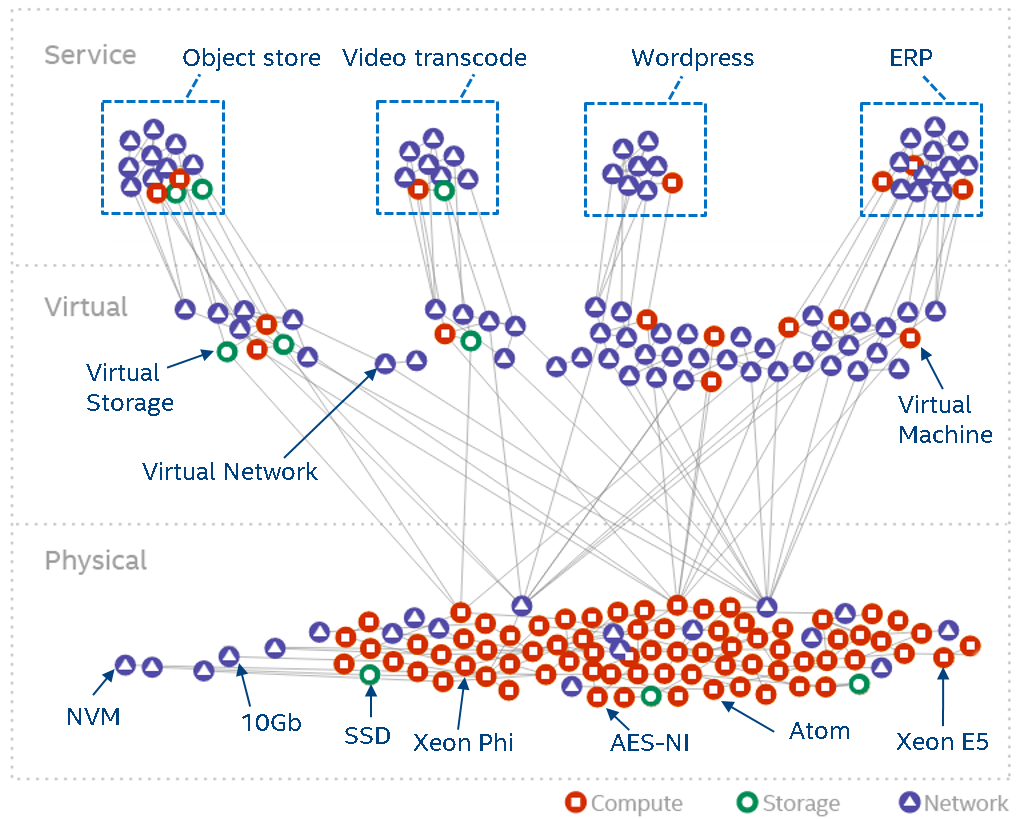
For data center management two major factors play a role: the workload (processes, tasks, containers, VMs, …) and the resources (CPUs, MEM, disks, power supplies, fans, …) under control. These form the service and resource landscape and are specific to the context of the individual data center. Different providers use different (heterogeneous) hardware (revisions) resource and have different customer groups running different workloads. The landscape overall describes how the entities in the data center are spatially connected. Telemetry systems allow for observing how they behave over time.
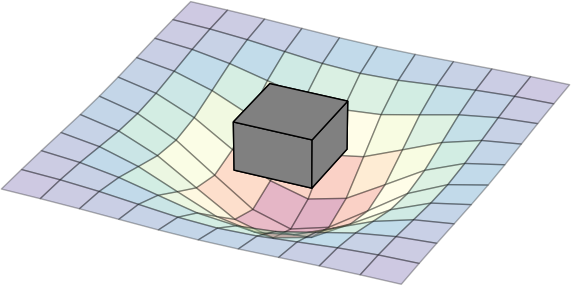
The following diagram can be seen as a metaphor on how the two interact: the workload create a impact on the landscape. The box represent a simple workload having an impact on the resource landscape. The landscape would be composed of all kind of different entities in the data center: from the air conditioning facility all the way to the CPU. Obviously the model taken here is very simple and in real-life a service would span multiple service components (such as load-balancers, DBs, frontends, backends, …). Different kinds of workloads impact the resource landscape in different ways.
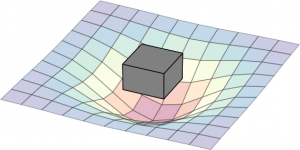
(Click to enlarge)
Current data center management systems are too focused on understanding resources behavior only and while external analytics capabilities exists, it becomes crucial that these capabilities need to move to the core of it and allow for observing and deriving insights for both the workload and resource behavior:
- workload behavior: Methodologies such as described in this paper, become key to understand the (heterogeneous) workload behavior and it’s service life-cycle over space and time. This basically means learning the shape of the workload – think of it as the form and size of the tile in the game Tetris.
- resource behavior: It needs to be understood how a) heterogeneous workloads impact the resources (especially in the case of over-subscription) and b) how features of the resource can impact the workload performance. Think of the resources available as the playing field of the game Tetris. Concept as described in this paper help understand how features like SR-IOV impact workload performance, or how to better dimension the service component’s deployment.
Deriving insights on how workloads behave during the life-cycle, and how resources react to that impact, as well as how they can enhance the service delivery is ultimately key to finding the best match between service components over space and time. Better matching (aka actually playing Tetris – and smartly placing the title on the playing field) allows for optimized TCO given a certain business objective. Hence it is key that the analytical capabilities for getting insights on workload and resource behavior move to the very core of the workload and resource management systems in future to make better insightful decisions. This btw is key on all levels of the system hierarchy: on single resource, hosts, resource group and cluster level.
Note: parts of this were discussed during the 9th workshop on cloud control.
Categories: Personal • Tags: Analytics, Cloud, data center, Machine Learning, Orchestration, Scheduling, SDI • Permalink for this article