Write your functions in Rust – with Azure & Rocket
May 14th, 2021 • Comments Off on Write your functions in Rust – with Azure & RocketRust is certainly one of the hot programming languages right now. Besides the cool feature set the language offers, companies – like Microsoft, Intel, Google, AWS, Facebook, etc. – embrace it: krustlet, rust-vmm, firecracker, etc. are all written in Rust. Then there is the newly formed Rust foundation and even in a recent survey by Stack Overflow it comes in on top. So why not programming your functions in Rust as well?
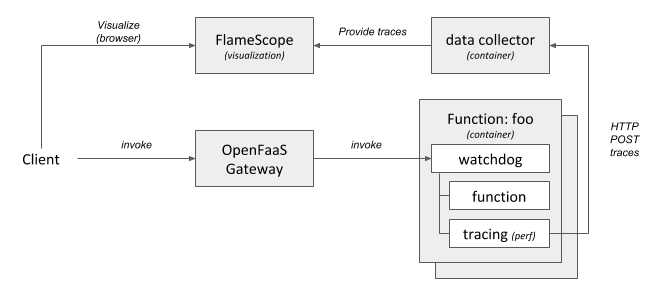
Most Cloud providers offer ways to write your function in Rust: AWS has a Rust based runtime for Lambda – using custom AWS Lambda runtimes, Azure offers it through what they call Azure Functions custom handlers. Both are reasonably similar in usage – as basically all you need to do is create an executable that is triggered by the frameworks when an Event arrives. Btw if you want to run it your function on-premises try the Rust template for OpenFaaS. We’ll look into how to integrate with Azure in the following sections.
Similarly to what is described in the Quickstart – it all starts with creating a new package using cargo:
$ cargo new rusty_function
Within the newly created package we need to edit the dependencies. As the function handler will be called through HTTP, a web framework is needed: rocket is one of the major web frameworks in the Rust ecosystem. Secondly serde can be used to serialize and deserialize data. The dependencies section of the Cargo.toml file will hence look something like this:
[dependencies] rocket = "^0.4.7" rocket_contrib = "^0.4.7" serde = "1.0" serde_derive = "1.0" serde_json = "1.0"
Writing the actual logic of the function is pretty straight forward – in main() start a web server that listens to a specific port – as provided by an environment variable:
fn main() {
let port_key = "FUNCTIONS_CUSTOMHANDLER_PORT";
let port: u16 = match env::var(port_key) {
Ok(val) => val.parse().expect("Whoops - not a int..."),
Err(_) => 8080,
};
let config = config::Config::build(config::Environment::Staging)
.address("127.0.0.1")
.port(port)
.finalize()
.unwrap();
rocket::custom(config)
.mount("/", routes![index, hello])
.launch();
}
Notice that two routes are setup in the second to last line of code. The one listening to HTTP GET calls to the main index page, and the actual function that implements our handler. The function for handling the request to the “main page” is not strictly necessary – I did notice however, that the Azure functions framework does make a single HTTP GET call on “/” when the functions starts. Implementing the index function is straight forward hence:
#[get("/")]
fn index() -> &'static str {
""
}
Before implementing the logic of the function itself, note that Azure expected the inputs and outputs to be formatted in a certain way – more details can be found here. Let’s focus on the output of the function and make sure it returns a JSON struct similar to this:
{
"returnvalue": {
"msg": "hello world"
},
"outputs": {
"res": "ok"
}
}
Not all of this will actually be returned to the function caller, but some of it is used by the Azure Functions framework itself – like outputs can contain entries you want to put in a Azure Queue storage, and logs (not shown in the example above) can be used to capture logging information. The actual ReturnValue is later on mapped to a response that is send to the function caller – more on that later.
We’ll use a set of structs to defined the JSON – and use the serde crate to enable serialization:
#[derive(Serialize)]
struct Response {
msg: String,
}
#[derive(Serialize)]
struct OutputBody {
res: String,
}
#[derive(Serialize)]
struct ResponseMessage {
returnvalue: Response,
outputs: OutputBody,
}
Obviously to be more conform with naming conventions in Rust – returnvalue should be called return_value, but Azure is looking for a CamelCase formatted ReturnValue – but luckily allows lower case naming too.
Implementing the actual function is straight forward now – notice the declaration of the /RustFunction route – that is later configured (becoming the name of the function), so the Azure Functions framework knows where to look for the function – more on that in the next steps.
#[post("/RustFunction")]
fn hello() -> json::Json<ResponseMessage> {
json::Json(ResponseMessage {
returnvalue: Response{msg: "hello world!".to_string()},
outputs: OutputBody{res: "ok".to_string()}
})
}
Make sure you use the nightly toolchain (it’s a rocket requirement atm) using the command rustup override set nightly. Also let’s make sure we get a static linked binary using MUSL by defining the following in the file .cargo/config:
[target.x86_64-unknown-linux-musl] linker = "rust-lld"
The code will compile now using: cargo build –release –target=x86_64-unknown-linux-musl, and we can run it standalone and even trigger the function if we want to. With a simple curl request the function can be tested locally. For the build command above to work you might need add the musl target to your system using rustup target add x86_64-unknown-linux-musl.
$ curl -X POST localhost:8080/RustFunction
{"returnvalue":{"msg":"hello world"},"outputs":{"res":"ok"}}
Integration with Azure Functions
So far everything has been pretty much generic, to make this function run on Azure some integration steps are required. The files required to do this can be created using the Azure Function Core Tools or probably with some help of your IDE. The command func new can be used to create the right templates. Make sure to configure it using the Custom Handler and HTTP Trigger – name the function e.g. RustyFunction matching the route defined earlier.
In the file host.json we now configure the field defaultExecutablePath to match our binary name – in our case rusty_function. The file RustyFunction/function.json should contain the following:
{
"bindings": [
{
"authLevel": "anonymous",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
Notice that within this configuration file we can define the HTTP verbs and also define how Azure Functions should handle the return values – note the $return that basically tells the framework to return whatever is set for the field ReturnValue (see JSON structure earlier) to the caller.
At this point in time, the function can be published to Azure or run locally using func start. Noticed that when calling the function through he framework we just get the “hello world” message back when testing it with curl:
$ curl -X POST http://localhost:7071/api/RustFunction -d ""
{"msg": "hello world"}
Performance
Finally let’s look at the performance of the function when being deployed on Azure. Therefore let’s compare a function written in Python and one written in Rust, both performing the same task: calculating the area of a circle given a radius.
This is not a totally fair comparison – as we are comparing apples to oranges a bit: the programming languages and their stacks are different, their deployment style differs (custom Linux based runtime vs optimized Python runtime). Also note we are only looking at HTTP triggers (coming with an overhead of serialization and deserialization, running a web framework etc.) – none of the other goodies that are available – and obviously hitting a function with a workload generator to look at performance goes a bit against the purpose of function: the frequency of invocation is really “high” and for this kind of call frequency a micro service style deployment might have been way better. Also some aspects of what influences latencies etc. are not in our control – the internet connection, the framework itself, etc.. Anyhow some numbers are better then no numbers.
Both functions have been deployed in Azure West Europe region – the following plot shows the latency percentiles for the function calls. And no surprise, Rust does well (but do notice the tail latency – that could really hurt overall performance – especially if you have multiple of these functions in your environment):

Another benefit of writing our function in Rust – the binary is tiny; Just about 5.6M in this case – so you can very easily package it up in a tiny container and run that in Azure, or OpenFaaS or … . Now it would be great to be able us other event triggers and concepts like function orchestration provided by e.g. Durable Functions as well in future.