AI reasoning & planning
January 4th, 2020 • Comments Off on AI reasoning & planningWith the rise of faster compute hardware and acceleration technologies that drove Deep Learning, it is arguable that the AI winters are over. However Artificial Intelligence (AI) is not all about Neural Networks and Deep Learning in my opinion. Even by just looking at the table of contents of the book “AI – A modern approach” by Russel & Norvig it can easily be seen, that the learning part is only one piece of the puzzle. The topic of reasoning and planning is equally – if not even more – important.
Arguably if you have learned a lot of cool stuff you still need to be able to reason over that gained knowledge to actually benefit from the learned insights. This is especially true, when you want to build autonomic systems. Luckily a lot of progress has been made on the topic of automated planning & reasoning, although they do not necessarily get the same attention as all the neural networks and Deep Learning in general.
To build an autonomous systems it is key to use these kind of techniques which allow for the system to adapt to changes in the context (temporal or spatial changes). I did work a lot on scheduling algorithms in the past to achieve autonomous orchestration, but now believe that planning is an equally important piece. While scheduling tells you where/when to do stuff, planning tells you what/how to do it. The optimal combination of scheduling and planning is hence key for future control planes.
To make this more concrete I spend some time implementing planning algorithms to test concepts. Picture the following, let’s say you have two robot arms. And you just give the control system the goal to move a package from A to B you want the system to itself figure out how to move the arms, to pick the package up & move it from A to B. The following diagram shows this:
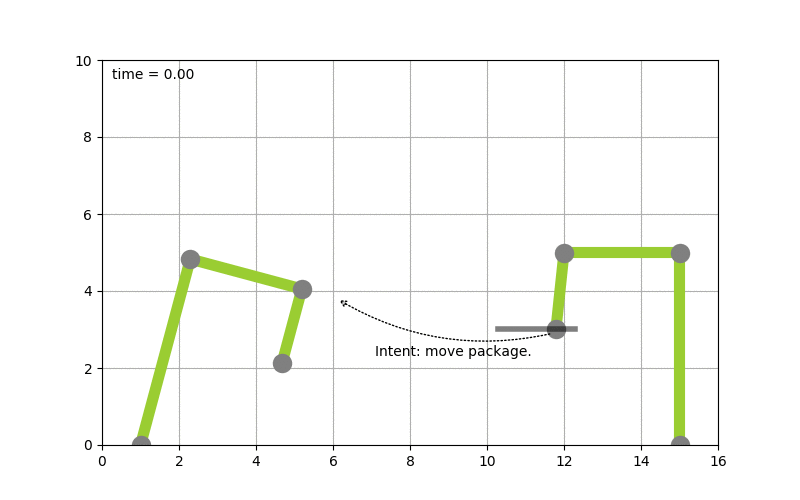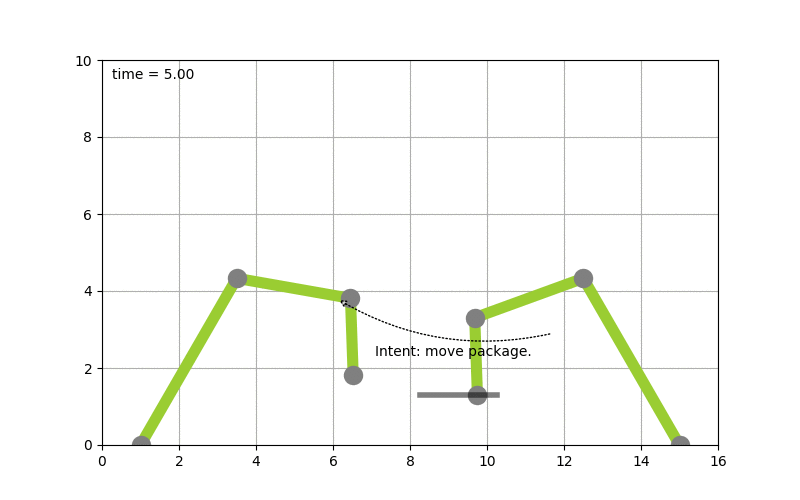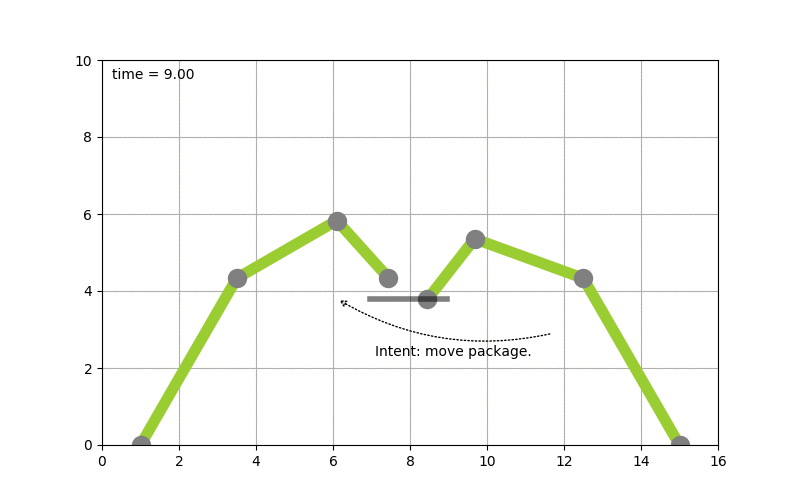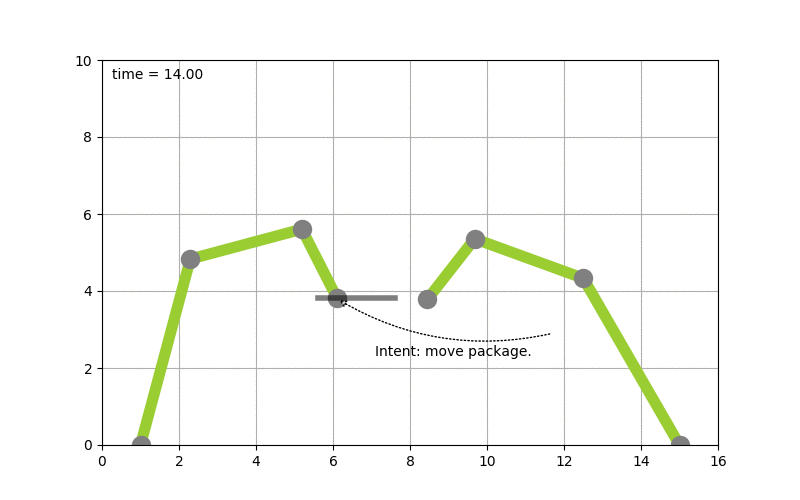
The goal of moving the package from A to B is converted into a plan by looking at the state of the packages which is given by it’s coordinates. By picking up the package and moving it around the state of the package hence changes. The movement of the robot arms is constraint, while the smallest part of the robot arm can move by 1 degree during each time step the bigger parts of the arm can move by 2 & 5 degrees respectively.
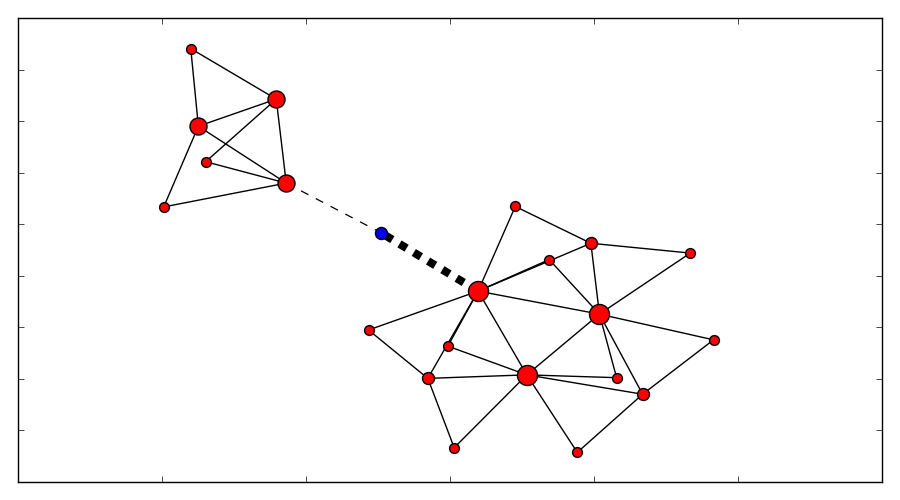
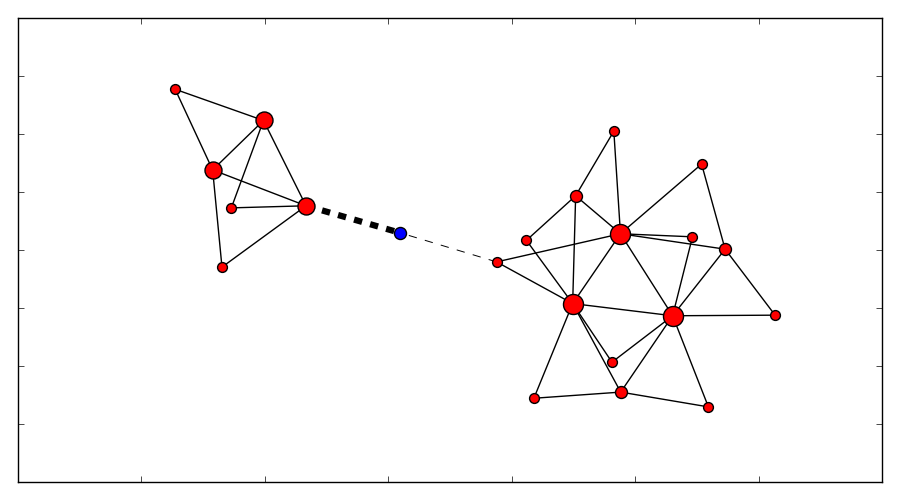
Based on this, a state graph can be generated. Where the nodes of the graph define the state of the package (it’s position) and the edges actions that can be performed to alter those states (e.g. move a part of an robot arm, pick & drop package etc.). Obviously not all actions would lead to an optimal solution so the weights on the edges also define how useful this action can be. On top of that, an heuristic can be used that allows the planning algorithm to find it’s goal faster. To figure out the steps needed to move the package from A to B, we need to search this state graph and the “lowest cost” path between start state (package is at location A) and end state (package is at location B) defines the plan (or the steps on what/how to achieve the goal). For the example above, I used D* Lite.
Now that a plan (or series of step) is known we can use traditional scheduling techniques to figure out in which order to perform these. Also note the handover of the package between the robots to move it from A to B this shows – especially in distributed systems – that coordination is key. More on that will follow in a next blog-post.