July 25th, 2016 • Comments Off on Insight driven resource management & scheduling
Future data center resource and workload managers – and their [distributed]schedulers – will require a new key integrate capability: analytics. Reason for this is the the pure scale and the complexity of the disaggregation of resources and workloads which requires getting deeper insights to make better actuation decisions.
For data center management two major factors play a role: the workload (processes, tasks, containers, VMs, …) and the resources (CPUs, MEM, disks, power supplies, fans, …) under control. These form the service and resource landscape and are specific to the context of the individual data center. Different providers use different (heterogeneous) hardware (revisions) resource and have different customer groups running different workloads. The landscape overall describes how the entities in the data center are spatially connected. Telemetry systems allow for observing how they behave over time.
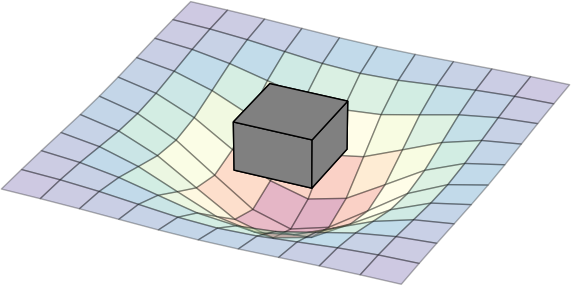
The following diagram can be seen as a metaphor on how the two interact: the workload create a impact on the landscape. The box represent a simple workload having an impact on the resource landscape. The landscape would be composed of all kind of different entities in the data center: from the air conditioning facility all the way to the CPU. Obviously the model taken here is very simple and in real-life a service would span multiple service components (such as load-balancers, DBs, frontends, backends, …). Different kinds of workloads impact the resource landscape in different ways.
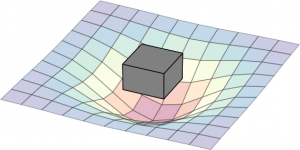
(Click to enlarge)
Current data center management systems are too focused on understanding resources behavior only and while external analytics capabilities exists, it becomes crucial that these capabilities need to move to the core of it and allow for observing and deriving insights for both the workload and resource behavior:
- workload behavior: Methodologies such as described in this paper, become key to understand the (heterogeneous) workload behavior and it’s service life-cycle over space and time. This basically means learning the shape of the workload – think of it as the form and size of the tile in the game Tetris.
- resource behavior: It needs to be understood how a) heterogeneous workloads impact the resources (especially in the case of over-subscription) and b) how features of the resource can impact the workload performance. Think of the resources available as the playing field of the game Tetris. Concept as described in this paper help understand how features like SR-IOV impact workload performance, or how to better dimension the service component’s deployment.
Deriving insights on how workloads behave during the life-cycle, and how resources react to that impact, as well as how they can enhance the service delivery is ultimately key to finding the best match between service components over space and time. Better matching (aka actually playing Tetris – and smartly placing the title on the playing field) allows for optimized TCO given a certain business objective. Hence it is key that the analytical capabilities for getting insights on workload and resource behavior move to the very core of the workload and resource management systems in future to make better insightful decisions. This btw is key on all levels of the system hierarchy: on single resource, hosts, resource group and cluster level.
Note: parts of this were discussed during the 9th workshop on cloud control.
Categories: Personal • Tags: Analytics, Cloud, data center, Machine Learning, Orchestration, Scheduling, SDI • Permalink for this article
March 24th, 2016 • Comments Off on A data center resource and service landscape
Telemetry and Monitoring systems give a great visibility into what is going on with the resources and services in a data center. Applying machine learning and statistical analysis to this massive data source alone often leads to results where it becomes clear correlation ain’t causation.
This brings the need for understanding of “what is connected to what” in a data center. By adding this topology as a data source, it is much easier to understand the relationships between two entities (e.g. a compute node and it’s Container/VM or a block storage and the NAS hosting it).
One of the ultimate goals we have here in Intel Labs is to put the data center on autopilot and hence we try to answer the Q:
how to efficiently define and maintain a physical and logical resource and service landscape enriched by operational/telemetry data, to support orchestration for optimized service delivery
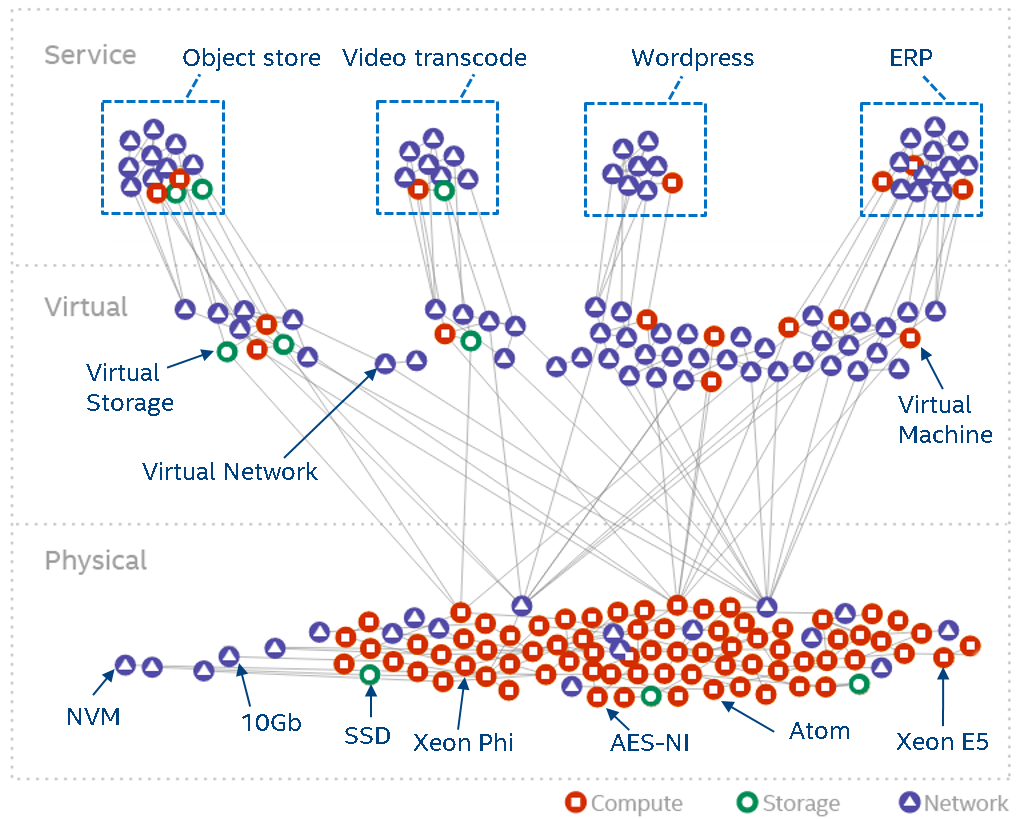
We have therefore come up with a landscape graph model. The graph model captures all the entities in a data center/SDI and makes their relations explicit. The following diagram shows the full-stack (from physical to virtual to service entities) landscape of a typical data center.
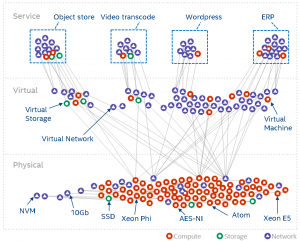
(Click to enlarge)
The graph model is automatically derived from systems such as OpenStack (or similar) and allow us to run all kinds of analytics – especially when we combine the graph model and annotate it with with data from telemetry systems.
As one example use case for using the landscape and annotate it with telemetry data, this paper shows a way to colour the landscape for anomaly detection.
Categories: Work • Tags: Cloud, data center, Orchestration, Scheduling, SDI • Permalink for this article
March 21st, 2016 • 1 Comment
Orchestration and Scheduling are not the newest topics, in fact they have been used in distributed systems forever (as in a couple of decades :-)). Systems like Mesos and Kubernetes (or offerings like Mantl) have brought advancements when it comes to dealing with scale. Other systems have a great background in scheduling and offer many (read a whole lot) policies for the same, this includes technologies like Grid Engine, LSF/OpenLava, etc.. Actually some of these technologies integrate with each other (like navops, Kubernetes and Mesos, OpenLava and Mesos, …), which makes it for example interesting when dealing with scheduling for space & order at the same time.
Next to pure demand, upcoming trends like CNCF & OCI as well as the introduction of Software Defined Infrastructure (SDI) drive the number of resources and services the Orchestrators and Controllers manage up. And the Question arises how to efficiently manage your data center – doing it by a human pressing a button is just not going to scale 🙂
Feedback control systems are a great start, however have some drawbacks. The larger the scale the more conflicts you might get between the feedback loops. The approaches might work up to rack level but probably not much beyond that. For large scale we need an approach which works along the lines of watch (e.g. by using snap), learn/decide (e.g. by using TAP) and act (See Jason Waxman’s keynote at OCP). This will eventually allow for a operatorless/humanless/driverless operations of the data center to support autonomous operations for scaling, healing and optimizing e.g. TCO.
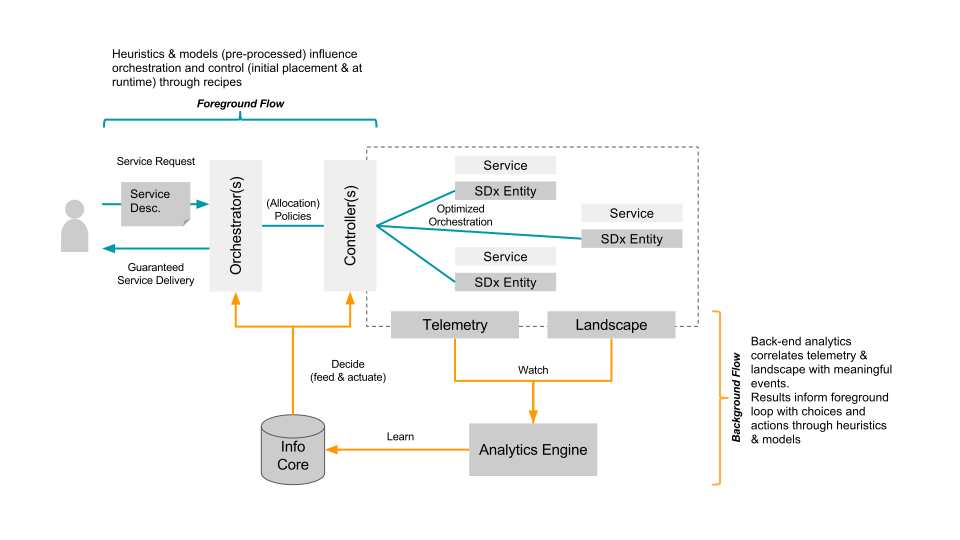
Within Intel Labs we have therefore come up with the concept of a foreground and a background flow. Within a continuously running background flow we observe (if needed over long time-periods) the data center with its resources and services and try to derive & update models heuristics (read: rule of thumb) continuously using analytics/machine learning. Within a foreground flow – which sometimes is denoted the fast loop as it needs to perform – we can than score against those heuristics/models in actions plans/recipes.
The action plan/recipes describe a process on how we deal with a initial placement or re-balancing event. The scoring will allow for making better initial placement (adding a workload) as well as re-balancing decisions (how/what/when to kill, migrate or tune the infrastructure). How to derive an heuristics is explained in a paper referenced below – the example within that is about to learn how to best place a VNF so that is makes optimal use of platform features such as SR-IOV. Multiple other heuristics can easily be imagined, like learning how many cores a certain workload needs.
The following diagram shows the background and foreground flow.
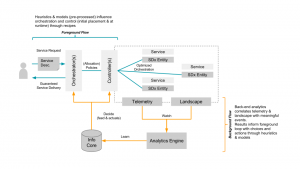
(Click to enlarge)
The heuristics are stored in an Information Core which based on the environment it is deployed in tunes itself. We’ve defined the concepts described here in a paper submitted to the Middleware 2015 conference. The researchers from Umea (who also run this highly recommended workshop) have used it and demonstrate an example use case in the same paper. For an example on how a background flow can help informing the foreground flow read this short paper. (Excuses for the paywall :-))
I’ll follow-up with some more blog posts detailing certain aspects of our latest work/research, like how the landscape works.
Categories: Work • Tags: Analytics, Cloud, data center, Machine Learning, Orchestration, Scheduling, SDI • Permalink for this article