September 18th, 2016 • Comments Off on Example 1: Intelligent Orchestration & Scheduling with Kubernetes
In the last blog I suggested that analytical capabilities need to move to the core of resource managers. This is very much needed for autonomous controlled large scale systems which figure out the biggest chunk of decisions to be made themselves. While the benefits from this might be obvious, the how to inject the insights/intelligence back into the resource manager might not be. Hence this blog post series documenting a bit how to let systems (they are just examples – trying to cover most domains :-)) like Kubernetes, OpenStack, Mesos, YARN and OpenLava make smarter decisions.
Background
The blog posts are going to cover some generic concepts as well as point to specific documentation bits of the individual resource managers. Some of this is already covered in past blog posts but to recap let’s look at the 5(+1) Ws for resource managers decision making (click to skip to the technical details):
- What decision needs to be made? – Decisions – and the actuations they lead too – can roughly be categorized into: doing initial placement of workloads on resources, the re-balancing of workload and resource landscapes (through either pausing/killing, migrating or tuning resource and workloads) and capacity planning activities (see ref).
- Who is involved? – The two driving forces for data center resource management are the customer and the provider. The customer looking for good performance and user experience while the provider looking for maximizing his ROI & lowering TCO of his resources. The customer is mostly looking for service orchestration (e.g. doesn’t care where and how the workload runs, as long as it performs and certain policies and rules – like for auto-scaling are adhered; or see sth like google’s instance size recommendation feature) while the provider looks at infrastructure orchestration of larger scale geo-distributed infrastructures (and the resources within) with multiple workloads from different customers (tenants are not equal btw – some are low playing non important workloads/customers some high paying important workloads/customers with priorities and SLAs).
- When does the decision/actuation apply? – Decisions can either be made immediately (e.g. an initial placement) or be more forward/backward looking (e.g. handle a maintenance/forklift upgrade request for certain resources).
- Where does the decision need to be made?- This is probably one of the most challenging questions. First of all this covers the full stack from physical resources (e.g. compute hosts, air-conditioning, …), software defined resources (e.g. virtual machines (VM), containers, tasks, …) all the way to the services the customers are running, as well as across domains of compute (e.g CPUs, VMs, containers, …), network (e.g. NICs, SDN, …) and storage (e.g. Disks, block/object storage, …). Decisions are done on individual resource, aggregated, group, data center or a global level. For example the NIC, the Virtual machine/container/tasks hosting the workload, or even the power supply can be actuated upon (feedback control is great for this). The next level actuations can be carried out on the aggregate level – in which a set of resources make up a compute hosts, ToR-switch, SAN (e.g. by tuning the TCP/IP stack in the kernel). Next up is the group level for which e.g. polices across a set of aggregates can be defined (e.g. over-subscription policy for all Xeon E5 CPUs, a certain rack determined to run small unimportant jobs vs. a rack needing to run high performance workloads). Next is the data center level for which we possibly want to enforce certain efficiency goals driven by business objective (e.g. lowering the PuE). Finally the global level captures possible multiple distributed data centers for which decisions need to be made which enable e.g. high availability and fault tolerance.
- Why does the decision need to be made? Most decision are made for efficiency reasons derived from business objectives of the provider and customer. This means ultimately the right balance between the customer deploying the workload and asking for performance and SLA compliance (customers tend to walk away if the provider doesn’t provide a good experience) and the provider improving TCO (not being able to have a positive cashflow normally lead to a provider running out of business).
- How is the decision/actuation made? This is the focus for this article series. In case it is determined a decision needs to be made, it needs to be clear on how to carry out the actual actuation(s) for all the kinds of decision that can be made described above.
Decision most of the time cannot be made generic – e.g. decisions made in HPC/HTC systems do not necessarily apply to a telco environments in which the workloads and resource are different. Hence the context of workloads and resource in place play a huge role. Ultimately Analytics which embraces the context (in all sorts and forms: deep/machine learning, statistical modelling, artificial intelligence, …) of the environment can drive the intelligence in the decision making through insights. This can obviously in multiple places/flows (see the foreground and background flow concepts here) and ultimately enables autonomous control.
Enhancing Kubernetes
For the Kubernetes examples let’s focus on a crucial decision point – doing the initial placement of a workloads (aka a POD in Kubernetes language) in a cluster. Although much of today’s research focuses on initial placement I’d urge everybody not to forget about all the other decisions that can be made more intelligent.
Like most Orchestrators and Schedulers Kubernetes follows a simple approach of filtering and ranking. After shortlisting possible candidates, the first step involves filtering those resource which do not meet the workloads demands. The second step involves prioritization (or ranking) of the resources best suited.
This general part is described nicely in the Kubernetes documentation here: https://github.com/kubernetes/kubernetes/blob/master/docs/devel/scheduler.md
This filtering part is mostly done based on capacities, while the second can involve information like the utilization. If you want to see this code have a look at the generic scheduling implementation: here. The available algorithms for filtering (aka predicates) and prioritization can be found here. The default methods that Kubernetes filters upon can be seen here: here – the default prioritization algorithms here: here. Note that weights can be applied to the algorithms based on your own needs as a provider. This is a nice way to tune and define how the resource under the control of the provider can be used.
While the process and the defaults already do a great job – let’s assume you’ve found a way on when and how to use an accelerator. Thankfully like most scheduling systems the scheduler in Kubernetes is extendable. Documentation for this can be found here. 3 ways are possible:
- recompile and alter the scheduler code,
- implement your own scheduler completely and run it in parallel,
- or implement an extension which the default scheduler calls when needed.
The first option is probably hard to manage in the long term, the second option requires you to deal with the messiness or concurrency while the third option is interesting (although adds latency to the process of scheduling due to an extra HTTP(s) call made). The default scheduler can basically call an external process to either ‘filter’ or ‘prioritize’. In the first case a list of possible candidate hosts is returned, in the the second case a prioritized list if returned. Now unfortunately the documentation get’s a bit vague, but luckily some code is available from the integration tests. For example here you can see some external filtering code, and here the matching prioritization code. Now that just needs to be served up over HTTP and you are ready to go, next to adding some configurations documented here.
So now an external scheduler extension can make a decisions if an accelerator should be assigned to a workload or not. The intelligent decision implemented in this extender could e.g. decide if an SR-IOV port is needed based on a bandwidth requirement, or if it is even a good idea to assign a Accelerator to a workload par the previous example.
Corrections, feedback and additional info are more then welcome. I’ve some scheduler extender code running here – but that is not shareable yet. I will update the post once I’ve completed this. In the next posts OpenStack (e.g. service like Nova, Watcher, Heat and Neutron), Mesos (how e.g. allocator modules can be used to inject smarts) and OpenLava (for which e.g. elims can be used to make better scheduling decisions) and obviously others will be introduced 🙂
Categories: Personal • Tags: Orchestration, Scheduling, SDI • Permalink for this article
July 25th, 2016 • Comments Off on Insight driven resource management & scheduling
Future data center resource and workload managers – and their [distributed]schedulers – will require a new key integrate capability: analytics. Reason for this is the the pure scale and the complexity of the disaggregation of resources and workloads which requires getting deeper insights to make better actuation decisions.
For data center management two major factors play a role: the workload (processes, tasks, containers, VMs, …) and the resources (CPUs, MEM, disks, power supplies, fans, …) under control. These form the service and resource landscape and are specific to the context of the individual data center. Different providers use different (heterogeneous) hardware (revisions) resource and have different customer groups running different workloads. The landscape overall describes how the entities in the data center are spatially connected. Telemetry systems allow for observing how they behave over time.
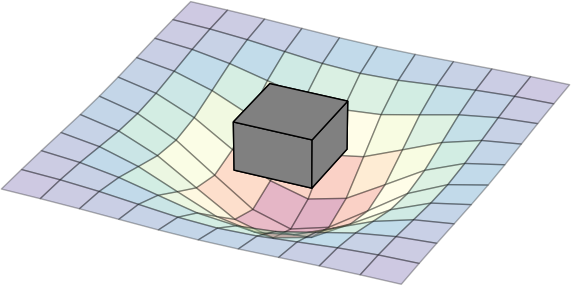
The following diagram can be seen as a metaphor on how the two interact: the workload create a impact on the landscape. The box represent a simple workload having an impact on the resource landscape. The landscape would be composed of all kind of different entities in the data center: from the air conditioning facility all the way to the CPU. Obviously the model taken here is very simple and in real-life a service would span multiple service components (such as load-balancers, DBs, frontends, backends, …). Different kinds of workloads impact the resource landscape in different ways.
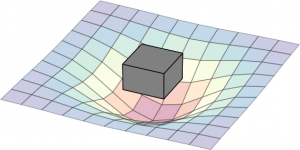
(Click to enlarge)
Current data center management systems are too focused on understanding resources behavior only and while external analytics capabilities exists, it becomes crucial that these capabilities need to move to the core of it and allow for observing and deriving insights for both the workload and resource behavior:
- workload behavior: Methodologies such as described in this paper, become key to understand the (heterogeneous) workload behavior and it’s service life-cycle over space and time. This basically means learning the shape of the workload – think of it as the form and size of the tile in the game Tetris.
- resource behavior: It needs to be understood how a) heterogeneous workloads impact the resources (especially in the case of over-subscription) and b) how features of the resource can impact the workload performance. Think of the resources available as the playing field of the game Tetris. Concept as described in this paper help understand how features like SR-IOV impact workload performance, or how to better dimension the service component’s deployment.
Deriving insights on how workloads behave during the life-cycle, and how resources react to that impact, as well as how they can enhance the service delivery is ultimately key to finding the best match between service components over space and time. Better matching (aka actually playing Tetris – and smartly placing the title on the playing field) allows for optimized TCO given a certain business objective. Hence it is key that the analytical capabilities for getting insights on workload and resource behavior move to the very core of the workload and resource management systems in future to make better insightful decisions. This btw is key on all levels of the system hierarchy: on single resource, hosts, resource group and cluster level.
Note: parts of this were discussed during the 9th workshop on cloud control.
Categories: Personal • Tags: Analytics, Cloud, data center, Machine Learning, Orchestration, Scheduling, SDI • Permalink for this article
January 2nd, 2016 • Comments Off on Graph stitching
Graph stitching describes a way to merge two graphs by adding relationships/edges between them. To determine which edges to add, a notion of node types is used (based on node naming would be easy :-)). Nodes with a certain type can be “stitched” to a node with a certain other type. As multiple mappings are possible, multiple result/candidate graphs are possible. A good stitch is defined by:
- all new relationships are satisfied,
- the resulting graph is stable and none of the existing nodes (entities) are impacted by the requested once.
So based on node types two graphs are stitched together, and than a set of candidate result graphs will be validated, to especially satisfy the second bullet.
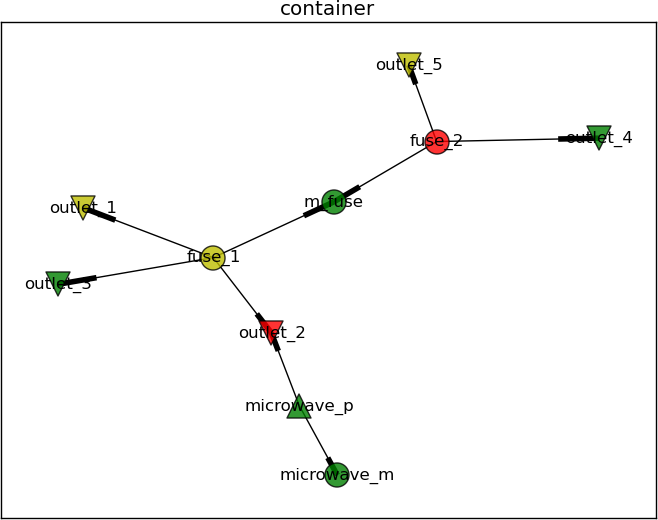
Let’s use an example to explain this concept a bit further. Assume the electrical “grid” in a house can be described by a graph with nodes like the power outlets and fuses, as well as edges describe the wiring. Some home appliances might be in place and connected to this graph as well. Hence a set of nodes describing for example a microwave (the power supply & magnetron), are in this graph as well. The edge between the power supply and the power outlet describe the power cable. The edge between the power supply and the magnetron is the internal cabling within the microwave. This graph can be seen in the following diagram.

(Click on enlarge)
The main fuse is connected to the fuses 1 & 2. Fuse 1 has three connected power outlets, of which outlet #2 is used by the microwave. Fuse 2 has two connected power outlets. Let’s call this graph the container from now on.
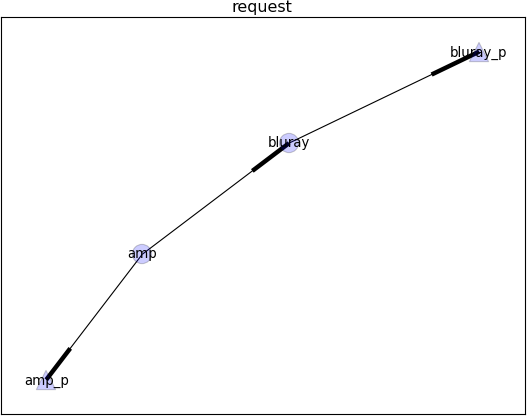
Now let’s assume a new HiFi installation (consisting of a blu-ray player and an amplifier) needs to be placed within this existing container. The installation itself can again be described using a simple graph, as shown in the following diagram.

(Click to enlarge)
Placing this request graph into the container graph now only requires that the power supplies of the player and amplifier are connected to the power outlets in the wall using a power cord. Hence edges/relationships are added to the container to stitch it to the request. This is done using the following mapping defition (The power_supply and power_outlet are values for the attribute “type” in the request & container graph):
{
"power_supply": "power_outlet"
}
As there is more than one possible results for stitching two graphs, candidates (there are 2 power supplies and 5 power outlets in the mix) need to be examined to see if they make sense (e.g. the fuse to which the microwave is connected might blow up if another “consumer” is added). But before getting to the validation, the number of candidates graphs should be limited using conditions.
For example the HiFi installation should be placed in the living room and not the kitchen. Hence a condition as follows (The power outlet nodes in the container graph have an attribute which is either set to ‘kitchen’ or ‘living’) can be defined:
condition = {
'attributes': [
('eq', ('bluray_p', ('room', 'living'))),
('eq', ('amp_p', ('room', 'living'))),
]
}
Also the amplifier should not be placed in the kitchen while the blu-ray player is placed in the living room. Hence the four nodes describing the request should share the same value for the room attribute. Also it can be defined that the power supplies of the player & amplifier should not be connected to the same power outlet:
condition = {
'compositions': [
('share', ('room', ['amp', 'amp_p', 'bluray', 'bluray_p'])),
('diff', ('amp_p', 'bluray_p'))
]
}
This already limits the number of candidate resulting graphs which need to validated further. During validation it is determined if a graph resulting out of a possible stitching falls under the definition of a good stitch (see earlier on). Within the container – shown early – the nodes are ranked – red indicating the power outlet or fuse heavy loaded; while green means the power outlet/fuse is doing fine. Now let’s assume no more “consumers” should be added to the second outlet connected to the first fuse as the load (rank) is to high. The high load might be caused by the microwave.
All possible candidate graphs (given the second condition described earlier) are shown in the following diagram. The titles of the graphs describe the outcome of the validation, indicating that adding any more consumers to outlet_2 will cause problems:

(Click to enlarge)
The container and request are represented as shown earlier, while the stitches for each candidate resulting graph are shown as dotted lines.
Graph stitcher is a simple tool implements a simple a stitching algorithm which generates the possible graphs (while adhering all kinds of conditions). These graphs can than be validated further based on different validators. For example by looking at number of incoming edges, node rank like described before, or any other algorithm. The tool hence can be seen as a simple framework (with basic visualisation support) to validate the concepts & usefulness of graph stitching.
Categories: Personal • Tags: Graph Stitching, Python • Permalink for this article
October 30th, 2014 • Comments Off on American Football Game Analysis
I’ve been coaching American Football for a while now and it is a blast standing on the sideline during game day. The not so “funny” part of coaching however – especially as Defense Coordinator – is the endless hours spend on making up stats of the offensive strategy of the opponent. Time to save some time and let the computer do the work.
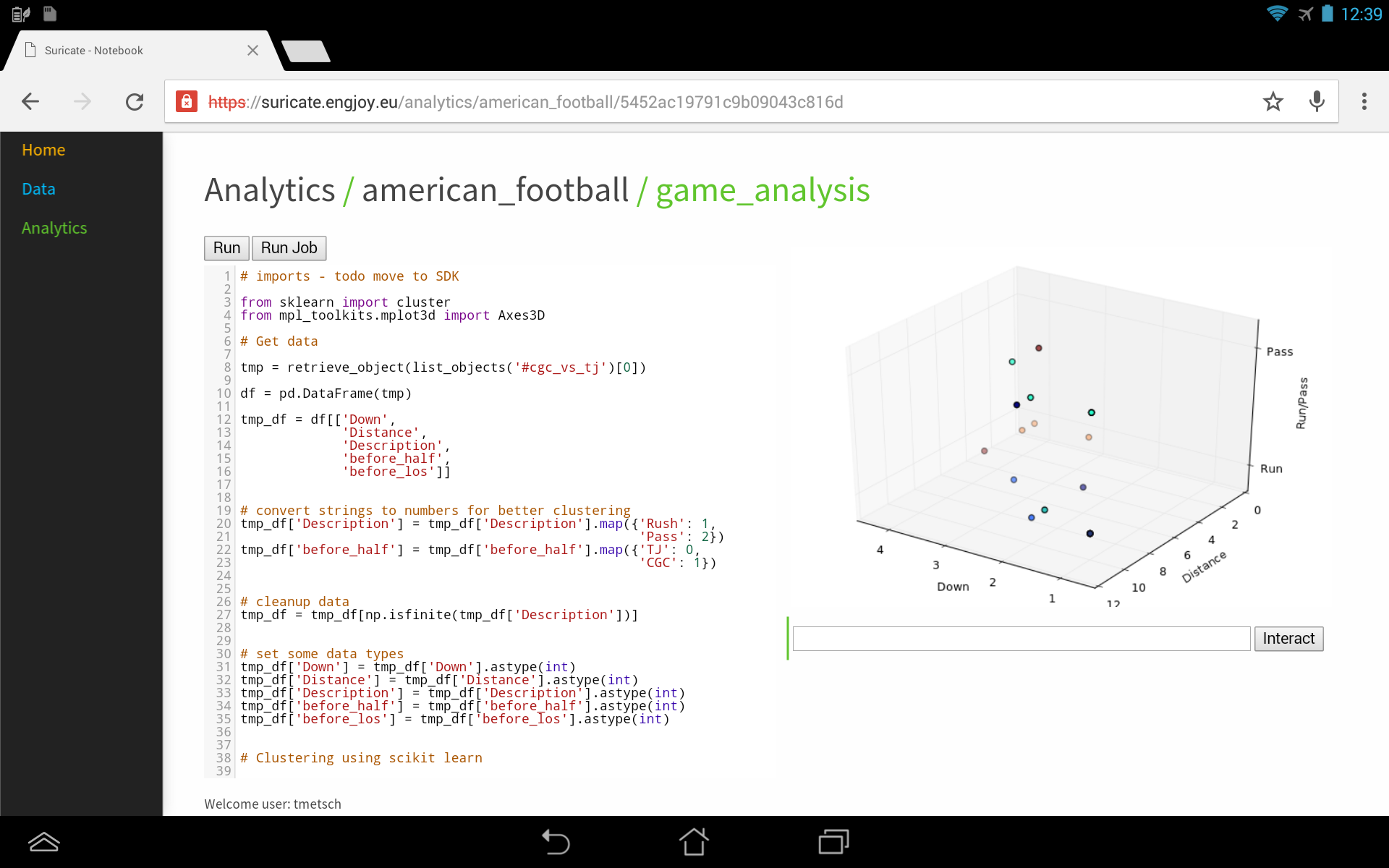
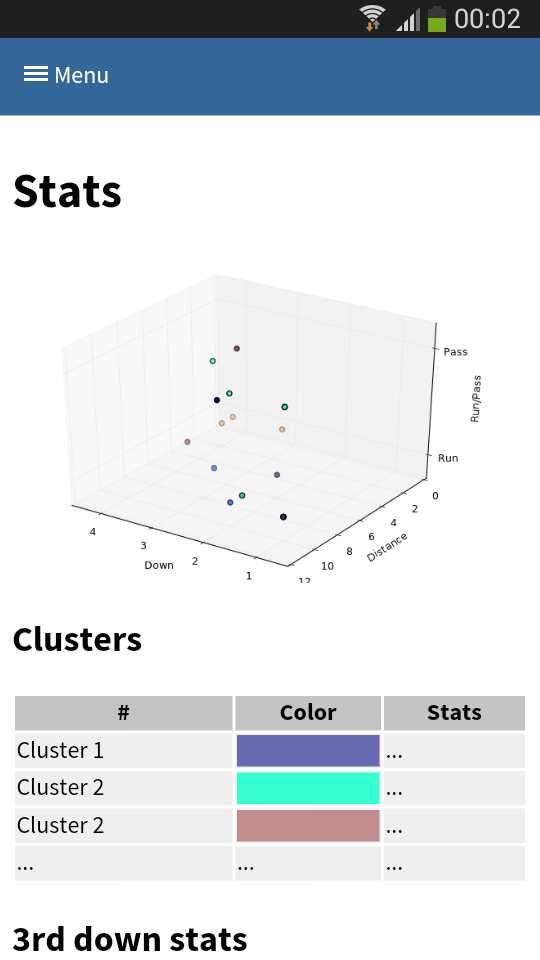
I’ve posted about how you could use suricate in a sports data setup past. The following screen shot show the first baby steps (On purpose not the latest and greatest – sry 🙂 ) of analyzing game data using suricate with python pandas and scikit-learn for some clustering. The 3D plot shows Down & Distance vs Run/Pass plays. This is just raw data coming from e.g. here.
The colors of the dots actually have a meaning in such that they represent a clustering of many past plays. The clustering is done not only on Down & Distance but also on factors like field position etc. So a cluster can be seen as a group of plays with similar characteristics for now. These clusters can later be used to identify a upcoming play which is in a similar cluster.
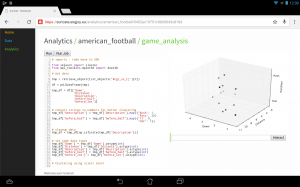
(Click to enlarge)
The output of this python script stores processed data back to the object store of suricate.
One of the new features of suricate is template-able dashboards (not shown in past screenshot). Which basically means you can create custom dashboards with fancy graphics (choose you poison: D3, matplotlib, etc):
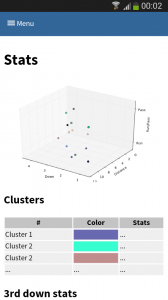
(Click to enlarge)
Again some data is left out for simplicity & secrecy 🙂
Making use of the stats
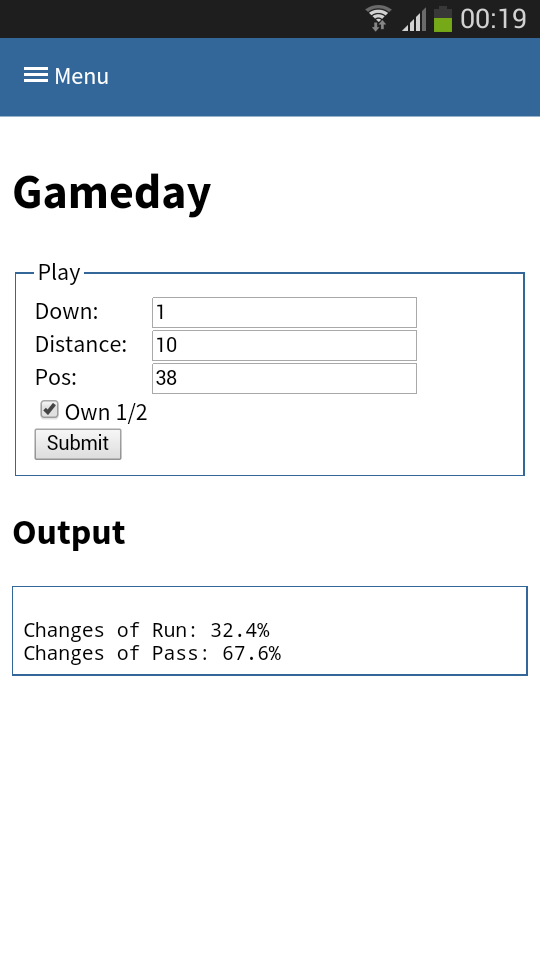
One part is understanding the stats as created in the first part. Secondly acting upon it is more important. With Tablets taking on sidelines, it is time to do the same & take the stats with you on game day. I have a simple web app sitting around in which current ball position is entered and some basic stats are shown.
This little web application does two things:
- Send a AMQP msg with the last play information to a RabbitMQ broker. Based on this new message new stats are calculated and stored back to the game data. This works thanks to suricate’s streaming support.
- Trigger suricate to re-calculate the changes of Run-vs-Pass in an upcoming play.
The webapp is a simple WSGI python application – still the hard work is carried out by suricate. Nevertheless the screenshot below shows the basic concept:
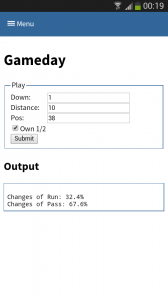
(Click to enlarge)
Categories: Personal, Sports • Tags: American Football, Data Science, Machine Learning, Python • Permalink for this article
September 21st, 2014 • 1 Comment
Suricate is an open source Data Science platform. As it is architected to be a native-cloud app, it is composed into multiple parts:
- a web frontend (which can be load-balanced)
- execution nodes which actually perform the data science tasks for the user (for now each user must have at least one exec node assigned)
- a mongo database for storage (which can be clustered for HA)
- a RabbitMQ messaging system (which can be clustered for HA)
Up till now each part was running in a SmartOS zone in my test setup or run with Openhift Gears. But I wanted to give CoreOS a shot and slowly get into using things like Kubernetes. This tutorial hence will guide through creating: the Docker image needed, the deployment of RabbitMQ & MongoDB as well as deployment of the services of Suricate itself on top of a CoreOS cluster. We’ll use suricate as an example case here – it is also the general instructions to running distributed python apps on CoreOS.
Step 0) Get a CoreOS cluster up & running
Best done using VagrantUp and this repository.
Step 1) Creating a docker image with the python app embedded
Initially we need to create a docker image which embeds the Python application itself. Therefore we will create a image based on Ubuntu and install the necessary requirements. To get started create a new directory – within initialize a git repository. Once done we’ll embed the python code we want to run using a git submodule.
$ git init
$ git submodule add https://github.com/engjoy/suricate.git
Now we’ll create a little directory called misc and dump the python scripts in it which execute the frontend and execution node of suricate. The requirements.txt file is a pip requirements file.
$ ls -ltr misc/
total 12
-rw-r--r-- 1 core core 20 Sep 21 11:53 requirements.txt
-rw-r--r-- 1 core core 737 Sep 21 12:21 frontend.py
-rw-r--r-- 1 core core 764 Sep 21 12:29 execnode.py
Now it is down to creating a Dockerfile which will install the requirements and make sure the suricate application is deployed:
$ cat Dockerfile
FROM ubuntu
MAINTAINER engjoy UG (haftungsbeschraenkt)
# apt-get stuff
RUN echo "deb http://archive.ubuntu.com/ubuntu/ trusty main universe" >> /etc/apt/sources.list
RUN apt-get update
RUN apt-get install -y tar build-essential
RUN apt-get install -y python python-dev python-distribute python-pip
# deploy suricate
ADD /misc /misc
ADD /suricate /suricate
RUN pip install -r /misc/requirements.txt
RUN cd suricate && python setup.py install && cd ..
Now all there is left to do is to build the image:
$ docker build -t docker/suricate .
Now we have a docker image we can use for both the frontend and execution nodes of suricate. When starting the docker container we will just make sure to start the right executable.
Note.: Once done publish all on DockerHub – that’ll make live easy for you in future.
Step 2) Getting RabbitMQ and MongoDB up & running as units
Before getting suricate up and running we need a RabbitMq broker and a Mongo database. These are just dependencies for our app – your app might need a different set of services. Download the docker images first:
$ docker pull tutum/rabbitmq
$ docker pull dockerfile/mongodb
Now we will need to define the RabbitMQ service as a CoreOS unit in a file call rabbitmq.service:
$ cat rabbitmq.service
[Unit]
Description=RabbitMQ server
After=docker.service
Requires=docker.service
After=etcd.service
Requires=etcd.service
[Service]
ExecStartPre=/bin/sh -c "/usr/bin/docker rm -f rabbitmq > /dev/null ; true"
ExecStart=/usr/bin/docker run -p 5672:5672 -p 15672:15672 -e RABBITMQ_PASS=secret --name rabbitmq tutum/rabbitmq
ExecStop=/usr/bin/docker stop rabbitmq
ExecStopPost=/usr/bin/docker rm -f rabbitmq
Now in CoreOS we can use fleet to start the rabbitmq service:
$ fleetctl start rabbitmq.service
$ fleetctl list-units
UNIT MACHINE ACTIVE SUB
rabbitmq.service b9239746.../172.17.8.101 active running
The CoreOS cluster will make sure the docker container is launched and RabbitMQ is up & running. More on fleet & scheduling can be found here.
This steps needs to be repeated for the MongoDB service. But afterall it is just a change of the Exec* scripts above (Mind the port setups!). Once done MongoDB and RabbitMQ will happily run:
$ fleetctl list-units
UNIT MACHINE ACTIVE SUB
mongo.service b9239746.../172.17.8.101 active running
rabbitmq.service b9239746.../172.17.8.101 active running
Step 3) Run frontend and execution nodes of suricate.
Now it is time to bring up the python application. As we have defined a docker image called engjoy/suricate in step 1 we just need to define the units for CoreOS fleet again. For the frontend we create:
$ cat frontend.service
[Unit]
Description=Exec node server
After=docker.service
Requires=docker.service
After=etcd.service
Requires=etcd.service
[Service]
ExecStartPre=/bin/sh -c "/usr/bin/docker rm -f suricate > /dev/null ; true"
ExecStart=/usr/bin/docker run -p 8888:8888 --name suricate -e MONGO_URI=<change uri> -e RABBITMQ_URI=<change uri> engjoy/suricate python /misc/frontend.py
ExecStop=/usr/bin/docker stop suricate
ExecStopPost=/usr/bin/docker rm -f suricate
As you can see it will use the engjoy/suricate image from above and just run the python command. The frontend is now up & running. The same steps need to be repeated for the execution node. As we run at least one execution node per tenant we’ll get multiple units for now. After bringing up multiple execution nodes and the frontend the list of units looks like:
$ fleetctl list-units
UNIT MACHINE ACTIVE SUB
exec_node_user1.service b9239746.../172.17.8.101 active running
exec_node_user2.service b9239746.../172.17.8.101 active running
frontend.service b9239746.../172.17.8.101 active running
mongo.service b9239746.../172.17.8.101 active running
rabbitmq.service b9239746.../172.17.8.101 active running
[...]
Now your distributed Python app is happily running on a CoreOS cluster.
Some notes
- Container building can be repeated without the need to destroy: docker build -t engjoy/suricate .
- Getting the log output of container to check why the python app crashed: docker logs <container name>
- Sometimes it is handy to test the docker run command before defining the unit files in CoreOS
- Mongo storage should be shared – do this by adding the following to the docker run command: -v <db-dir>:/data/db
- fleetctl destroy <unit> and list-units are you’re friends 🙂
- The files above with simplified scheduling & authentication examples can be found here.
Categories: Personal • Tags: Analytics, Cloud, CoreOS, Data Science, Python, Software Engineering, Tech • Permalink for this article

{kind=link}